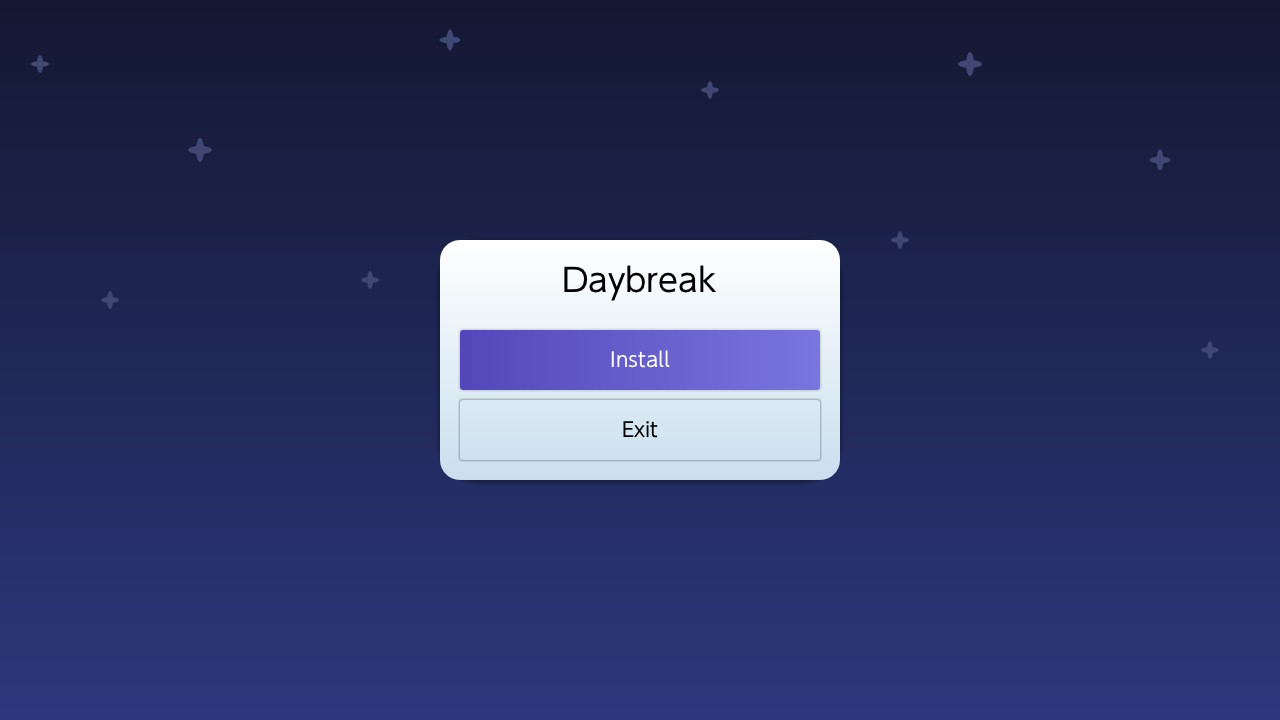
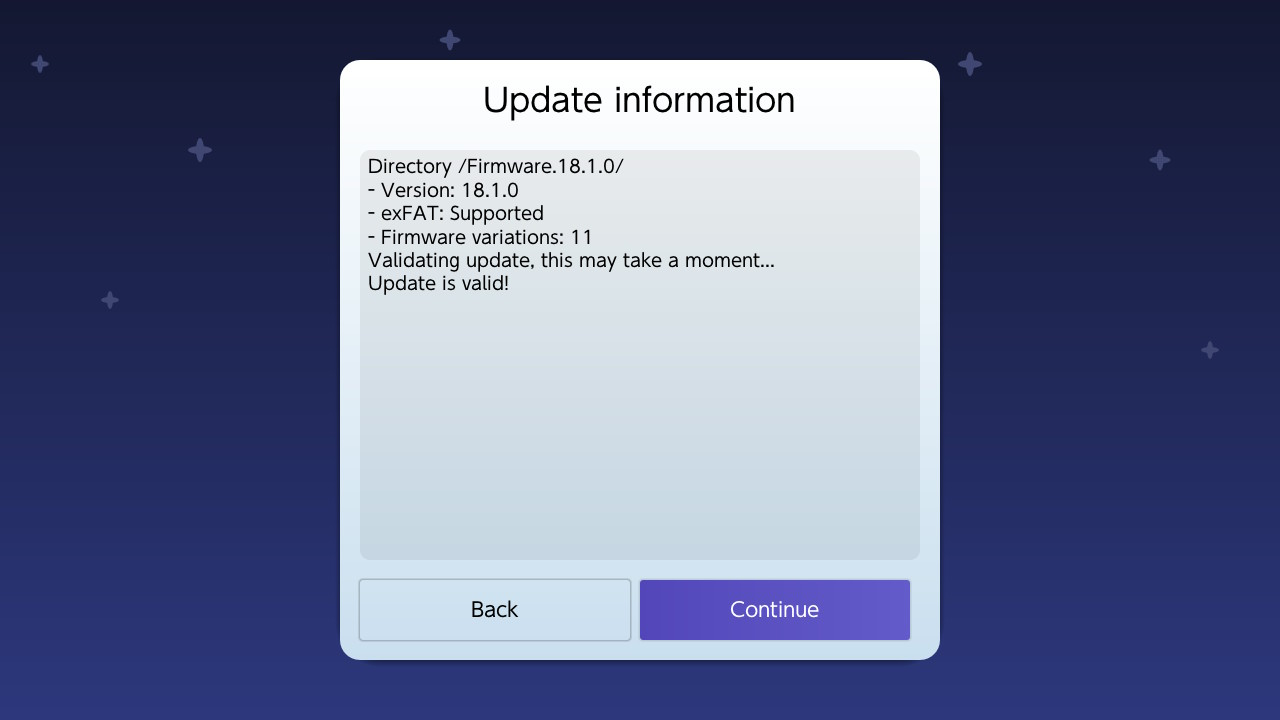
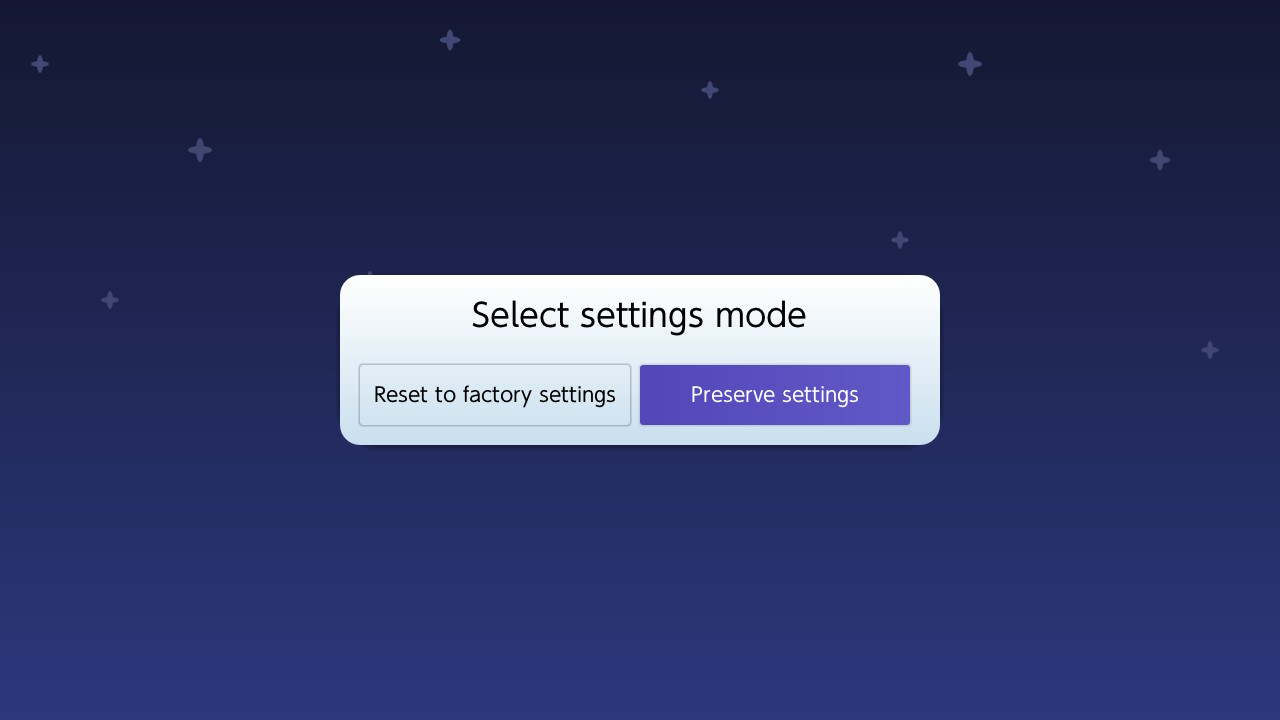
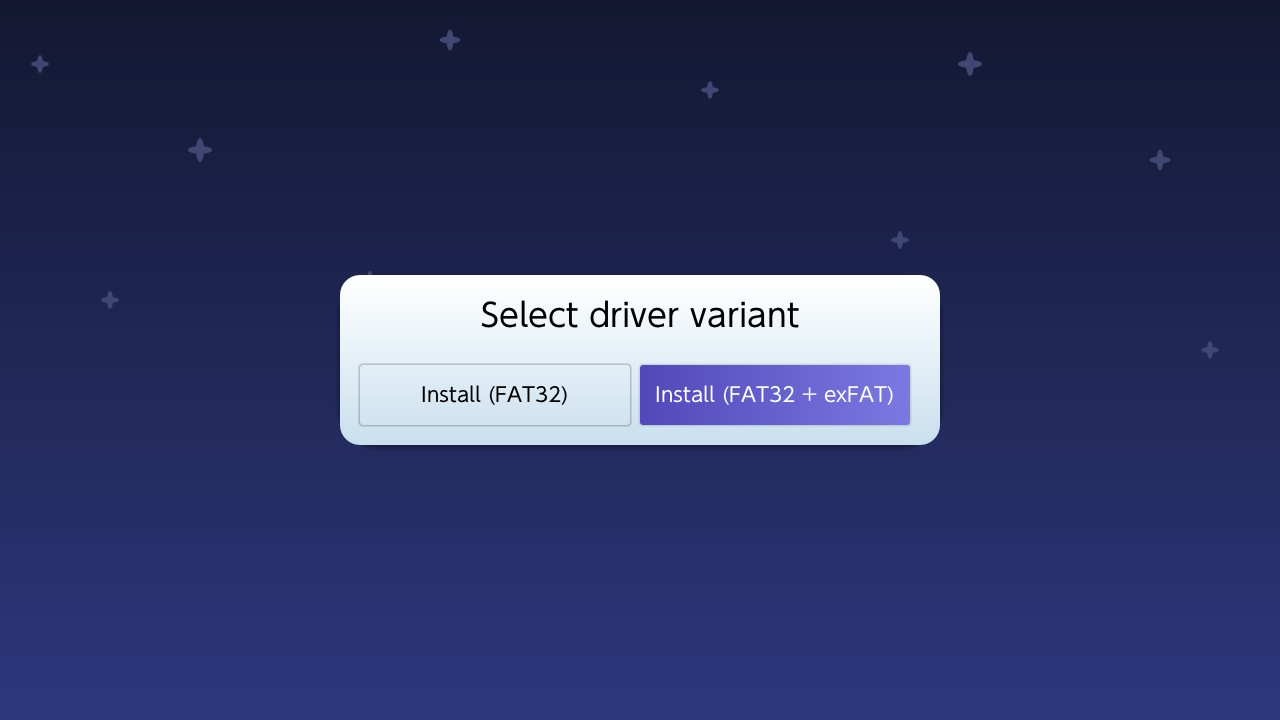
publicstaticvoidmain(String[] args) { finalTesta=newTest(); a = newTest(); } } // Main.java:10: error: cannot assign a value to final variable a // a = new Test(); // ^ // 1 error
测试篇
问题一
以 UT 为例,怎么保证测试分支全部覆盖?
1
利用 True/False 标注以及 Jacoco 等测试工具综合判断。
问题二
IT 的 Case 是自己写的吗?根据什么写的?
1
根据画面 シナリオ 编写。
问题三
A && B || C,这种条件下,如果 A 是 True、B 是 False、C 是 True,最终结果是什么?
在IDE中通过选中单元测试路径,点击右键选择run test和点击maven中的test是有区别的。在Maven执行测试的过程中,是不允许测试cases访问其他项目的测试类和其他项目的resources下文件的。也就是说,在a/src/test/java下的测试用例,是不能引用b/src/test/java中的类的,同时也不允许访问b/src/test/resources下的资源的。但是在IDE中的Run Unit Test几乎是没有这样的限制的。